Hoe werkt ChatGPT achter de schermen? Uitleg in 3 stappen
Hoe werkt ChatGPT achter de schermen? In drie stappen van vraag naar antwoord, zonder technische ruis en met concrete gevolgen voor hoe jij het gebruikt.
Hoe werkt ChatGPT eigenlijk? Die vraag krijgen we in elke KMO-workshop. Niet uit technische nieuwsgierigheid, maar omdat het antwoord je helpt om de tool realistisch in te zetten. Wie denkt dat ChatGPT “weet” wat hij zegt, wordt teleurgesteld door hallucinaties. Wie begrijpt hoe het werkt, gebruikt het precies waar het excelleert — en vermijdt het waar het faalt.
In dit artikel ontleden we wat er gebeurt tussen het moment dat je op “verzenden” klikt en het moment dat het antwoord verschijnt. Drie stappen. Geen jargon. Wel concrete implicaties voor je werk.

Wat is ChatGPT eigenlijk?
ChatGPT is een chatbot van OpenAI die draait bovenop een Large Language Model, een type AI-model dat tekst begrijpt en genereert. Wat een LLM precies is, hoe het getraind wordt en hoe AI werkt, leggen we uit in dit artikel over. Voor dit artikel volstaat dat je weet: ChatGPT is de gebruikersinterface, het LLM (in ChatGPT’s geval de GPT-familie) doet het rekenwerk.
Als je iets intypt in ChatGPT, gebeuren er achter de schermen drie dingen in een paar seconden. Opsplitsen, voorspellen, opbouwen. We bekijken elke stap.
Stap 1: je vraag wordt opgesplitst in tokens
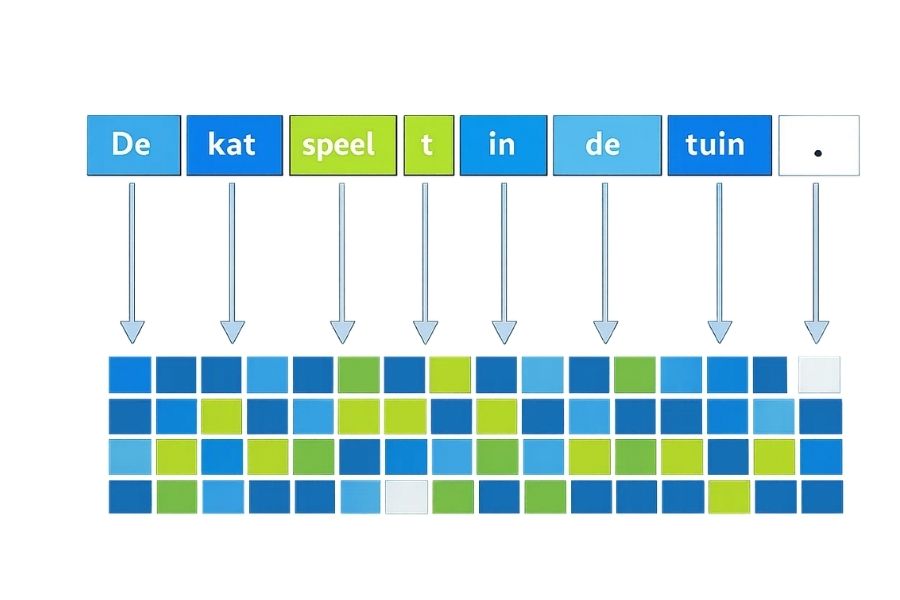
ChatGPT leest geen woorden zoals wij. Hij leest tokens: kleine tekst-eenheden die soms een heel woord zijn, soms een deel van een woord, soms zelfs een leesteken. “Goedemorgen” wordt bijvoorbeeld opgesplitst in “Goed”, “e”, “morgen”. Een gemiddelde Nederlandse zin van tien woorden bestaat uit ongeveer vijftien tot twintig tokens.
Deze stap heet tokenization. Hij gebeurt razendsnel, maar hij is belangrijk om twee redenen. Eén: het verklaart waarom ChatGPT soms raar kapt in zeldzame woorden of eigennamen — die tokens herkent hij minder goed. Twee: de prijs van betaalde API-toegang wordt per token gerekend, niet per woord. Wie met ChatGPT via de API werkt in een bedrijfscontext, rekent dus altijd in tokens.
Elke token krijgt ook een positie: waar staat hij in jouw vraag? Dat geeft ChatGPT de volgorde om de zin te begrijpen.
Stap 2: het model voorspelt het volgende token
Dit is waar de magie (of het misverstand) zit. ChatGPT genereert zijn antwoord door telkens het waarschijnlijkst volgende token te berekenen op basis van alles wat ervoor kwam. Niet het “juiste” token. Niet het “ware” token. Het waarschijnlijkste token, gegeven de context.
Concreet: je vraagt “Wat is de hoofdstad van België?” Het model heeft tijdens zijn training miljarden keren gezien dat woorden als “Brussel” volgen op een zin met “hoofdstad” en “België”. Het voorspelt dus “Brussel” met zeer hoge waarschijnlijkheid. Makkelijke vraag, statistisch onvermijdelijk antwoord.
Maar stel dat je vraagt “Wat is het omzetcijfer van bakkerij Janssens in Antwerpen?” Die informatie stond niet in de trainingsdata. Het model probeert alsnog tokens te genereren die waarschijnlijk lijken — een getal, een munteenheid, een jaar — maar die waarschijnlijkheid is niet gebaseerd op kennis, maar op patroonherkenning. Het resultaat is wat wij een hallucinatie noemen: een antwoord dat overtuigend klinkt maar verzonnen is. We gaan daar dieper op in in ons artikel over waarom AI soms fouten maakt.
Belangrijke implicatie: ChatGPT heeft geen waarheidsmechanisme. Hij heeft een waarschijnlijkheidsmechanisme. Die twee verwarren is het grootste risico bij zakelijk gebruik.
Stap 3: het antwoord wordt token per token opgebouwd
Wat je in de ChatGPT-interface ziet — de woorden die letter per letter verschijnen — is geen cosmetisch effect. Dat ís hoe het model werkt. Token wordt gegenereerd, wordt toegevoegd aan de context, waarna het volgende token berekend wordt op basis van alles wat nu in de context staat (jouw vraag plus alles wat hij tot dan toe zelf genereerde).
Deze lussende manier van werken verklaart waarom ChatGPT soms halverwege een antwoord van gedachten verandert, of logisch consistent blijft over lange passages. Elke nieuwe token “ziet” alles wat ervoor stond en probeert daarbij te passen.
Het model heeft ook een context window: een maximale hoeveelheid tokens die het in één gesprek kan onthouden. Bij oudere modellen was dat paar duizend tokens, bij de nieuwste versies honderdduizenden. Als een gesprek voorbij die limiet gaat, begint de oudste inhoud stilletjes weg te vallen. Dat verklaart waarom lange ChatGPT-conversaties soms eerdere instructies “vergeten”.
Waarom ChatGPT soms fout gaat
Nu je de drie stappen kent, vallen de typische ChatGPT-fouten logisch op hun plek. We sommen de vier meest voorkomende op.
- Hallucinaties. Het model vult gaten op met waarschijnlijk-klinkende onzin. Namen, cijfers, bronnen, jaartallen — vooral bij niche-vragen. Volledige uitleg in ons artikel over hallucinaties.
- Verouderde kennis. Een model kent enkel wat er in zijn trainingsdata stond, tot een bepaalde datum (de “knowledge cutoff”). Actuele gebeurtenissen ná die datum kent hij niet, tenzij hij met webzoeken is uitgebreid.
- Incorrecte rekensommen of logica. Omdat het model tokens voorspelt, niet cijfers optelt, kan het bij complexe berekeningen fouten maken. Voor rekenwerk gebruik je best een rekentool of code-interpreter, niet de default tekstinterface.
- Inconsistentie op lange gesprekken. Als de context-window vol raakt, valt oudere informatie weg. Het model “vergeet” dan eerdere instructies uit hetzelfde gesprek.
Geen van deze fouten is een bug — ze zijn inherent aan hoe het systeem werkt. Ze wegwerken vraagt geen betere ChatGPT, maar een betere gebruiker.
Wat betekent dit voor hoe je ChatGPT gebruikt?
Als je de drie stappen begrijpt, volgen er vijf praktische regels voor zakelijk gebruik.
1. Geef context mee.
Het model voorspelt tokens op basis van wat je hem toont — dus hoe meer relevante context, hoe beter de voorspelling. “Schrijf een e-mail” geeft mindere output dan “Schrijf een e-mail aan een klant die een offerte twee weken geleden ontving en nog niet antwoordde. Toon: vriendelijk, niet-drammerig. Lengte: 80 woorden.” Hoe je dat principe systematisch toepast, staat in onze gids over prompt engineering.
2. Factcheck kritische output.
Feiten, cijfers, citaten, bronvermeldingen: altijd verifiëren voor je ze publiceert of naar een klant stuurt. Voor een KMO-eigenaar die content produceert is dit het verschil tussen een handige assistent en een reputatierisico.
3. Gebruik het waar patronen dominant zijn.
Samenvatten, herschrijven, variaties maken, format omzetten, brainstormen — daar presteert ChatGPT sterk, omdat die taken exact matchen met patroonvoorspelling. Originele research of precisieberekening: daar niet.
4. Kies je model bewust.
ChatGPT is niet het enige spel in de stad — Claude en Gemini hebben andere sterktes. Onze vergelijking van de drie grote LLM-chatbots helpt je kiezen voor jouw use case.
5. Hou de mens in de lus (Human in the loop).
Voor klantgerichte output blijft menselijke controle standaard, niet optie. Niet omdat AI onbetrouwbaar is, maar omdat de reputatiekost van één foute automatische mail groter is dan de tijdswinst van honderd correcte. Meer over die afweging en andere AI-keuzes voor ondernemers lees je in onze AI-gids voor Belgische ondernemers.
Samengevat: ChatGPT in één zin
ChatGPT is een tokenvoorspeller die op basis van jouw input telkens het waarschijnlijkst volgende stukje tekst berekent — indrukwekkend goed als je hem goed stuurt, teleurstellend als je denkt dat hij weet. Wie deze drie stappen in zijn hoofd heeft, prompt vanzelf beter, factcheckt wat ertoe doet, en haalt meer uit de tool dan wie hem als een orakel behandelt.

Volgende stap
Hoe werkt Chatgpt? Dat weet jij nu… de logische volgende stap: is leren hoe je hem aanstuurt. Lees onze uitleg over prompt engineering — hoe je betere resultaten krijgt, inclusief vijf principes en drie kant-en-klare templates.