Wat is een transformer model?
Het transformer model is de architectuur waarop vrijwel alle moderne AI-taalmodellen zijn gebouwd. Dit artikel legt uit wat een transformer is, hoe het attentiemechanisme werkt, en waarom dit relevant is voor bedrijven die AI inzetten.

Het transformer model is de architectuur waarop bijna alle moderne AI-taalmodellen zijn gebouwd — van ChatGPT tot Claude tot Gemini. Zonder transformers zou de AI-boom van de afgelopen jaren niet hebben plaatsgevonden. Dit artikel legt uit wat een transformer is, hoe het attentiemechanisme werkt, en waarom dit relevant is voor iedereen die AI-tools begrijpelijk wil houden zonder technisch te worden.
Je hoeft de wiskunde niet te begrijpen om te profiteren van de inzichten. Het gaat om de kernideeën die verklaren waarom moderne AI zo goed is in taal — en waar de grenzen liggen.
Wat is een transformer model?
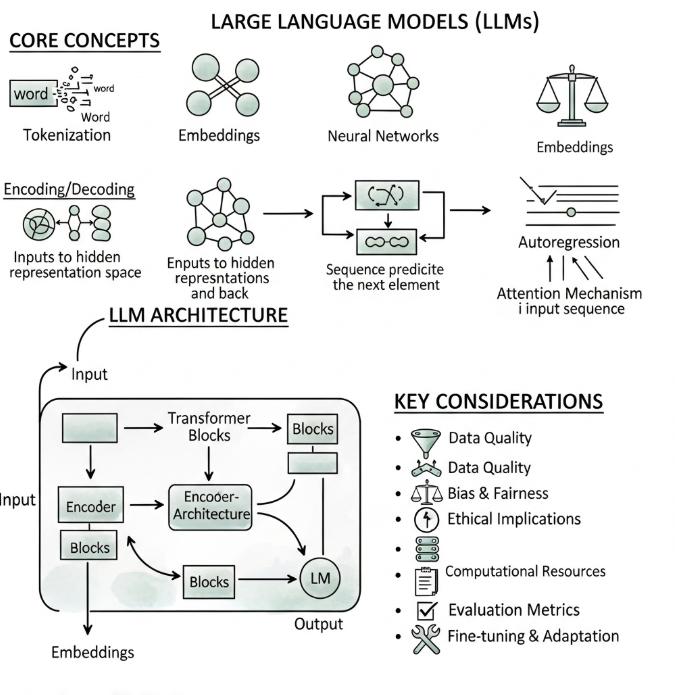
Een transformer is een type neuraal netwerk dat in 2017 werd geïntroduceerd in het paper “Attention Is All You Need” van Google-onderzoekers. Vóór transformers gebruikten taalmodellen recurrente netwerken (RNNs) — architecturen die tekst woord voor woord verwerken, zoals een mens die een zin leest van links naar rechts.
Het probleem met die aanpak: bij lange teksten verliest het model de vroeg gelezen informatie. Een RNN dat de twintigste zin verwerkt, “herinnert” zich de eerste zin al amper. Dat beperkt de kwaliteit van het model bij langere documenten.
Transformers lossen dit op met een fundamenteel andere aanpak: ze verwerken alle woorden in een tekst gelijktijdig en berekenen voor elk woord hoe relevant elk ander woord is. Dat is de kern van het “attentiemechanisme”.
Het attentiemechanisme: aandacht als navigatie
Stel dat het model de zin “De bank aan de rivier was aangenaam” moet begrijpen. Het woord “bank” is dubbelzinnig — het kan een financiële instelling of een zitbank zijn. Het attentiemechanisme laat het model alle andere woorden in de zin tegelijk bekijken en berekenen welke contextwoorden het meest informatief zijn voor de interpretatie van “bank”. In dit geval signaleert “rivier” sterk dat het om een zitbank gaat.
Dat attentieproces gebeurt voor elk woord in de tekst, tegelijkertijd. Dat maakt transformers veel efficiënter te parallelliseren op GPU’s dan RNNs — en daarmee sneller te trainen op grote datasets. Het is precies waarom NVIDIA’s parallel-processing architectuur zo goed aansluit bij transformers als model-architectuur.

Van transformer naar groot taalmodel
Een groot taalmodel (LLM) is een transformer die is opgeschaald — meer parameters, meer trainingsdata, meer rekenkracht. GPT-4 heeft naar schatting meer dan een biljoen parameters. Claude 3 Opus werkt in een vergelijkbare orde van grootte. Die schaal is wat de kwaliteitssprong verklaart ten opzichte van vroegere modellen.
De parameters in een LLM zijn de numerieke gewichten die het model heeft geleerd tijdens training. Ze slaan impliciet informatie op over taal, feiten, redenering en stijl — niet als een database van feiten, maar als patronen in de gewichten. Dat is ook waarom LLMs kunnen “hallucineren”: ze genereren tekst op basis van statistisch waarschijnlijke patronen, niet op basis van directe kennisopslag.
Voor meer technische context over hoe tokens en embeddings werken binnen dit systeem: Tokens en embeddings: hoe AI tekst begrijpt.
Waarom transformer modellen schaalbaar zijn
Een van de meest opmerkelijke eigenschappen van transformers is dat ze schalen met data en rekenkracht op een bijna voorspelbare manier. Meer parameters, meer trainingsdata en meer rekenkracht leveren consistent betere modellen op — een relatie die Anthropic, OpenAI en anderen hebben beschreven als “scaling laws”.
Dat is fundamenteel anders dan eerdere AI-architecturen waarbij schaling na een bepaald punt geen lineaire kwaliteitsverbetering meer opleverde. Voor transformers geldt die wet nog steeds, al worden de returns kleiner naarmate de modellen groter worden. GPT-4 presteert duidelijk beter dan GPT-3 — maar de sprong van GPT-2 naar GPT-3 was percentueel groter.
Die schaalbaarheid verklaart ook de race naar grotere modellen: bedrijven die meer kunnen investeren in rekenkracht en data, bouwen betere modellen. Dat is de fundamentele economische dynamiek achter de dominantie van grote technologiebedrijven in de frontier-AI-markt.
Transformer model varianten: encoder, decoder, encoder-decoder
Niet alle transformers zijn hetzelfde gebouwd. Er zijn drie hoofdvarianten die elk voor andere taken zijn geoptimaliseerd.
Encoder-only transformers (zoals BERT) zijn gespecialiseerd in tekst begrijpen: sentiment-analyse, classificatie, named entity recognition. Ze zijn sterk in taken waarbij de input begrepen moet worden, maar geen lange tekst gegenereerd hoeft te worden.
Decoder-only transformers (zoals GPT, Claude, Gemini) zijn gespecialiseerd in tekst genereren. Ze voorspellen het volgende token op basis van alle vorige tokens in de context. Dat maakt ze sterk voor conversatie, schrijven, samenvatten en code genereren.
Encoder-decoder transformers (zoals de originele architectuur voor machinevertaling) zijn ontworpen voor taken waarbij input en output een ander formaat hebben — vertaling, samenvatting, vraag-antwoord met expliciete invoer.
Voor de meeste zakelijke AI-toepassingen werkt u met decoder-only modellen — de generatieve modellen die u kent via ChatGPT, Claude of Gemini.
Wat transformers niet kunnen
Transformers zijn niet alomvattend. Ze redeneren niet zoals mensen — ze herkennen patronen op een zodanige schaal dat het op redeneren lijkt. Ze hebben geen intern geheugen buiten het context window: na het gesprek zijn alle vorige berichten vergeten tenzij expliciet opgeslagen. En ze zijn kostbaar in gebruik: elke inferentie vereist significante rekenkracht, wat de prijzen van AI-diensten mede bepaalt. Nieuwe architecturen (zoals Mamba of hybride modellen) proberen sommige van deze beperkingen aan te pakken, maar transformers blijven voorlopig de dominante standaard.
De oorspronkelijke paper die het transformer model introduceerde is beschikbaar via arXiv: “Attention Is All You Need” (Vaswani et al., 2017) — een vereiste lectuur voor iedereen die dieper wil gaan. Voor het bredere technische kader: Hoe werkt AI? Simpel uitgelegd voor beginners. En voor de overkoepelende gids: de AI-gids voor Belgische ondernemers.