Wat is machine learning en hoe werkt het?
Heldere uitleg van machine learning: wat het is, de drie hoofdtypes, hoe een model leert, en hoe ML zich verhoudt tot AI en deep learning.

Een goede machine learning uitleg hoeft niet ingewikkeld te zijn. De kerngedachte past in één zin: een computer leert patronen herkennen uit voorbeelden, in plaats van dat je hem elke regel stap voor stap voorschrijft. Alles wat daarna komt — deep learning, neurale netwerken, LLM’s — zijn verfijningen op dat idee. In dit artikel gaan we de belangrijkste concepten door zonder jargon, met voorbeelden uit de praktijk.
We beginnen bij een werkbare definitie, lopen daarna door de drie hoofdtypes, kijken hoe een model eigenlijk ‘leert’, en eindigen met wat dit betekent voor de AI-tools die je vandaag gebruikt.
Machine learning uitgelegd: een werkbare definitie
Machine learning (ML) is een tak van artificiële intelligentie waar een algoritme uit data leert om voorspellingen of beslissingen te maken, zonder expliciet geprogrammeerd te zijn voor elke individuele situatie. Het verschil met traditionele software zit in één woord: generalisatie. Een klassiek programma doet wat je schrijft. Een ML-model doet wat het uit voorbeelden heeft afgeleid.
Concreet: stel dat je een e-mail wil classificeren als spam of niet-spam. Je kunt regels schrijven (“als onderwerp bevat ‘gratis iPhone’ → spam”). Dat werkt, tot spammers hun wording aanpassen. Een ML-model krijgt in plaats daarvan tienduizenden voorbeelden van spam en niet-spam, en leert zelf welke patronen ertoe doen. Het model blijft werken als spammers hun vocabulaire veranderen, zolang de achterliggende patronen herkenbaar blijven.
Dit principe ligt onder elke moderne AI-toepassing die je kent: aanbevelingssystemen op Netflix, fraudedetectie bij je bank, gezichtsherkenning in je telefoon en de taalgeneratie van ChatGPT. Dezelfde bouwsteen, verschillende schalen.

De drie hoofdtypes machine learning
Niet elke ML-techniek werkt hetzelfde. Afhankelijk van welke data je hebt en wat je wil bereiken, kies je een van drie benaderingen.
Supervised learning
Het model leert uit gelabelde voorbeelden. Je geeft het duizenden e-mails waarvan telkens staat of het spam is of niet. Het model zoekt zelf de kenmerken die ertoe doen. Dit is de meest gebruikte vorm in het bedrijfsleven: fraude-detectie, kredietbeoordeling, medische beeldclassificatie, vraagvoorspelling. Bij een supervised learning-opzet staat of valt de kwaliteit met je labels. Slechte labels, slecht model.
Unsupervised learning
Hier zijn er geen labels. Het model krijgt een hoop ruwe data en moet er zelf structuur in vinden. Typische toepassingen zijn klantsegmentatie (welke groepen zitten er in mijn klantenbestand?), anomaliedetectie (welk gedrag wijkt af?) en aanbevelingen op basis van vergelijkbaar gedrag. Unsupervised is krachtig wanneer je zelf nog niet weet welke patronen erin zitten, maar vraagt wel om interpretatie achteraf.
Reinforcement learning
Het model leert door te doen, met beloningen en straffen als feedback. Typische voorbeelden: een game-AI die leert schaken door miljoenen partijen tegen zichzelf te spelen, een robot die leert lopen, een AI die voorraadbeslissingen optimaliseert. Voor KMO’s is reinforcement learning zelden direct relevant, behalve als het verpakt zit in tools voor optimalisatie (advertenties, pricing).
Hoe ‘leert’ een ML-model eigenlijk?
Het woord ‘leren’ is hier metaforisch. Er is geen begrip, geen bewustzijn, geen herinnering. Een ML-model is onder de motorkap een grote set wiskundige parameters die tijdens de training herhaaldelijk bijgesteld worden tot de output zo dicht mogelijk bij het gewenste resultaat ligt.
In de praktijk verloopt training in drie fasen:
- Voorwaartse pass. Het model krijgt een input en produceert een eerste voorspelling op basis van zijn huidige parameters.
- Verliesberekening. Het verschil tussen die voorspelling en het correcte antwoord wordt uitgedrukt in een getal (de ‘loss’).
- Bijsturing. Alle parameters worden een piepklein beetje aangepast in de richting die de loss verlaagt. Miljoenen keren herhaald.
Bij een LLM zoals ChatGPT is dit principe niet wezenlijk anders, alleen op een monumentale schaal: miljarden parameters, terabytes tekstdata, weken tot maanden rekenen op duizenden GPU’s. Het resultaat is een model dat woorden kan voorspellen op basis van patronen in vrijwel de hele publieke tekstbibliotheek. Maar de bouwsteen is dezelfde als die spam-filter: input, voorspelling, loss, bijsturing.
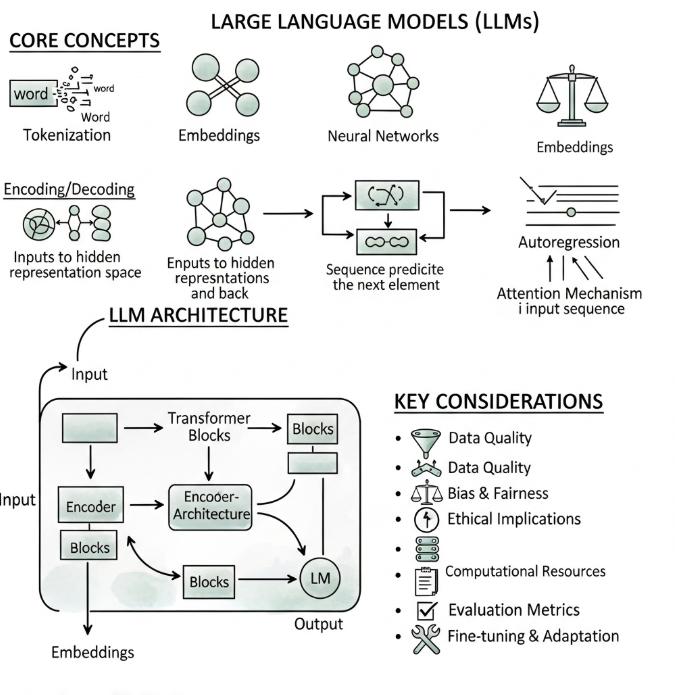
ML versus AI versus deep learning: het verschil
Deze termen worden vaak door elkaar gebruikt alsof ze synoniemen zijn. Dat zijn ze niet. Drie concentrische cirkels, van buiten naar binnen:
- AI (artificiële intelligentie): de overkoepelende term. Elk systeem dat taken uitvoert die traditioneel intelligentie van een mens vereisen.
- Machine learning: een subveld van AI waar modellen uit data leren. De meeste moderne AI is machine learning.
- Deep learning: een subveld van machine learning dat gebruikmaakt van meerlagige neurale netwerken. Dit is wat de doorbraak in beeld- en taalverwerking mogelijk maakte, en de basis vormt voor LLM’s.
Praktisch: als iemand zegt “we gebruiken AI”, bedoelen ze vandaag bijna altijd ML. Als ze zeggen “we gebruiken deep learning”, bedoelen ze een specifieke techniek binnen ML. De woorden zijn losser dan ze klinken.
Concreet voorbeeld: de spam-filter
Eén voorbeeld om alles samen te brengen. Een spam-filter in 2026 is typisch een supervised classifier, vaak gebaseerd op deep learning. De trainingsfase gaat zo: het model krijgt miljoenen gelabelde e-mails (‘spam’ of ‘ham’), leert de kenmerken die scheiden, en wordt daarna losgelaten op nieuwe inkomende mail. Wat voor een gebruiker onzichtbaar blijft, is de constante herscholing. Spammers evolueren, dus het model wordt maandelijks (of vaker) bijgetraind met nieuwe voorbeelden.
Dit is meteen een les voor KMO’s die met ML willen starten: een model is geen eenmalige investering. Data-verzameling, labeling en hertraining zijn lopende kosten. Wie daar niet op inricht, krijgt na een jaar een model dat trager degradeert dan de wereld om hem heen verandert.
Wat betekent dit voor de AI-tools die je gebruikt?
Elke AI-tool die je vandaag gebruikt — ChatGPT, Claude, Midjourney, GitHub Copilot, Gemini — is een machine learning model. Drie praktische implicaties:
- Kwaliteit hangt af van de trainingsdata. Een model weet niets buiten wat het gezien heeft. Dit verklaart waarom LLM’s fouten maken over recente gebeurtenissen of niche-onderwerpen.
- Het model heeft geen begrip. Het herkent patronen, redeneert niet zoals jij. Daarom hallucineert het soms plausibel-klinkende onzin.
- Het blijft evolueren. Nieuwe versies komen voort uit meer data, betere algoritmes en meer rekenkracht. Wat vandaag niet kan, kan volgende maand wel.
Voor achtergrond over hoe deze bouwstenen uiteindelijk een tool als ChatGPT maken, is hoe AI werkt, simpel uitgelegd een goed vervolgartikel. Wie specifiek meer wil weten over hoe LLM’s zich verhouden tot andere modellen, houdt best de LLM-uitleg in de gaten.
Samengevat
Machine learning is de manier waarop moderne AI-systemen functioneren: modellen die uit data leren in plaats van expliciete regels te volgen. Drie hoofdtypes (supervised, unsupervised, reinforcement), één gemeenschappelijk principe (train, evalueer, bijsturen, herhaal) en een groeiend scala aan toepassingen, van spamfilters tot taalgeneratie. Wie deze basis vastheeft, begrijpt 80% van de AI-nieuwsberichten die hij leest.