Hoe werkt AI? Een duidelijke uitleg van Large Language Models (LLM’s)
AI lijkt vandaag magisch. Je stelt een vraag en krijgt een antwoord dat vaak verrassend goed, logisch en zelfs menselijk aanvoelt. Maar achter die “magie” zit geen bewustzijn of echte intelligentie zoals wij die kennen — er zit een complex systeem van wiskunde, data en…
AI lijkt vandaag magisch. Je stelt een vraag en krijgt een antwoord dat vaak verrassend goed, logisch en zelfs menselijk aanvoelt. Maar achter die “magie” zit geen bewustzijn of echte intelligentie zoals wij die kennen — er zit een complex systeem van wiskunde, data en patronen achter.
Om AI echt te begrijpen, moet je één stap terugzetten en kijken naar hoe deze modellen opgebouwd zijn. Want een tool zoals ChatGPT is geen black box, maar het resultaat van een reeks goed gestructureerde processen: van het opsplitsen van tekst in tokens, tot het analyseren van context via neurale netwerken, en het voorspellen van het volgende woord in een zin.
In dit artikel nemen we je stap voor stap mee in de werking van Large Language Models (LLM’s). Je ontdekt hoe AI tekst “begrijpt”, waarom het eigenlijk een voorspellingsmachine is, en welke bouwstenen ervoor zorgen dat deze technologie vandaag zo krachtig is.
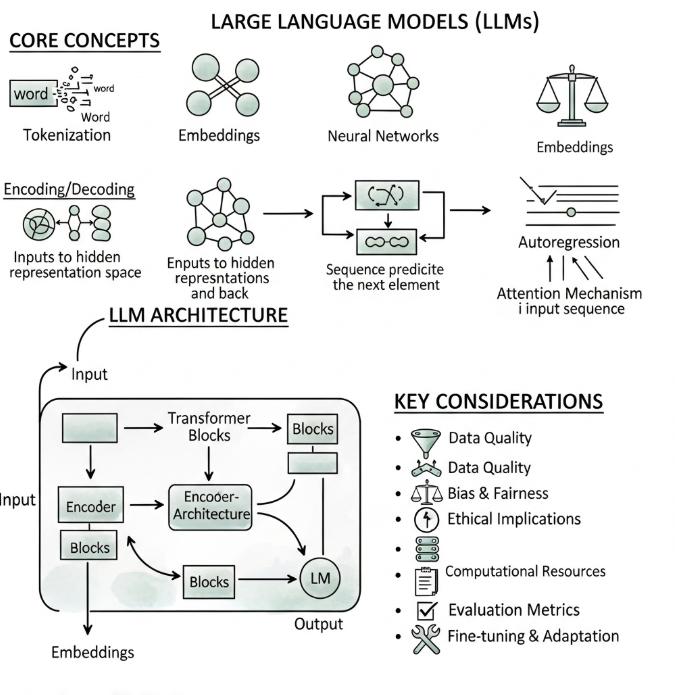
1. CORE CONCEPTS: de fundamenten van een LLM
Tokenization
Links bovenaan zie je Tokenization. Dat is de eerste stap.
Een LLM leest meestal geen volledige woorden zoals wij dat doen. Het splitst tekst op in kleinere stukjes, zogenaamde tokens. Dat kunnen woorden zijn, maar ook delen van woorden, leestekens of zelfs losse tekens.
Bijvoorbeeld:
- “marketingstrategie” kan één token zijn
- maar het kan ook opgesplitst worden in meerdere tokens
- ook spaties en interpunctie spelen mee
Waarom is dit belangrijk? Omdat een model niet rechtstreeks met “taal” werkt, maar met een reeks tokens. Alles wat daarna gebeurt, vertrekt vanuit die tokenreeks.
Embeddings
Daarna zie je Embeddings. Dat zijn numerieke representaties van tokens of woorden. Met andere woorden: elk token wordt omgezet in een soort vector, een lijst van getallen.
Die vectoren proberen betekenis of context mee te dragen. Woorden die inhoudelijk dicht bij elkaar liggen, liggen in die vectorruimte vaak ook dichter bij elkaar.
Bijvoorbeeld:
- “huis”, “woning” en “appartement” zullen dichter bij elkaar zitten
- “baksteen” kan in sommige contexten ook relatief dichtbij zitten
- “ruimtevaart” waarschijnlijk veel verder
De afbeelding toont embeddings als een netwerkachtig icoon, maar het belangrijkste idee is: taal wordt omgezet in wiskundige representaties.
Neural Networks
Dan zie je Neural Networks. Dat is het mechanisme waarmee het model patronen leert in enorme hoeveelheden tekstdata.
Een neuraal netwerk bestaat uit lagen die signalen verwerken en transformeren. In LLM’s gaat het vandaag vrijwel altijd om een specifiek type architectuur: de transformer. Dat wordt verderop in de afbeelding ook nog apart getoond.
Belangrijk: het model “kent” taal niet zoals een mens. Het heeft tijdens training statistische patronen geleerd:
- welke woorden vaak samen voorkomen
- welke structuren typisch zijn
- welke vervolgen waarschijnlijk zijn in een bepaalde context
Het schaal-icoon rechtsboven
Rechtsboven staat opnieuw “Embeddings”, maar het icoon lijkt eerder op een weegschaal en past inhoudelijk waarschijnlijk beter bij bias, afweging of evaluatie dan bij embeddings. Dat deel van de afbeelding is dus niet helemaal consistent. In een strikte uitleg zou daar eerder een ander concept staan, of minstens een betere label.
2. Encoding / Decoding: van input naar interne representatie en terug
Onder de basisconcepten staat Encoding/Decoding.
Dat verwijst naar het proces waarbij inputtekst eerst wordt omgezet naar een interne vorm die het model kan verwerken, en vervolgens terug wordt vertaald naar output.
Inputs to hidden representation space
Wanneer jij tekst invoert, ziet het model in eerste instantie geen “betekenisvolle zin”, maar tokens. Die tokens worden vervolgens omgezet naar embeddings en verder verwerkt tot een verborgen representatie of hidden representation.
Dat is een interne toestand van het model waarin allerlei informatie over context, grammatica, verbanden en waarschijnlijkheden vervat zit.
Je kan dat zien als:
- inputtekst gaat binnen
- het model bouwt intern een rijke mathematische representatie op
- vanuit die representatie bepaalt het model wat logisch volgt
Inputs to hidden representations and back
Het tweede schemaatje bouwt daarop voort: de tekst gaat niet alleen “naar binnen”, maar wordt intern meerdere keren getransformeerd en uiteindelijk opnieuw terug vertaald naar tokens als output.
Dat “and back” is belangrijk, want een LLM moet niet alleen input analyseren, maar ook nieuwe output genereren die voor mensen leesbaar is.
3. Sequence prediction: waarom een LLM eigenlijk een voorspellingsmachine is
In het midden van de afbeelding staat een pijldiagram met de tekst “Sequence predictie the next element”. Dat bevat een typfout, maar de bedoeling is duidelijk: een LLM voorspelt het volgende element in een reeks.
Dat is misschien wel het belangrijkste principe van allemaal.
Een LLM doet in essentie dit:
- het krijgt een reeks tokens
- het berekent welk volgend token het meest waarschijnlijk is
- daarna neemt het dat token mee in de context
- en voorspelt opnieuw het volgende token
- enzovoort
Dus als jij vraagt:
“Wat zijn de belangrijkste AI bedrijven?”
Dan voorspelt het model niet in één keer het volledige antwoord. Het genereert dat antwoord token voor token.
Die ogenschijnlijk simpele aanpak wordt extreem krachtig wanneer:
- het model gigantisch groot is
- het op enorme datasets is getraind
- de context slim verwerkt wordt
4. Autoregression: output bouwen stap voor stap
Rechts in het midden zie je Autoregression.
Autoregressie betekent hier: het model gebruikt zijn eerdere output telkens opnieuw als context voor de volgende stap.
Dus:
- het voorspelt token 1
- token 1 wordt deel van de nieuwe context
- dan voorspelt het token 2
- token 2 komt erbij
- enzovoort
Dat verklaart meteen waarom LLM’s soms:
- mooi opgebouwde zinnen maken
- consistent verder schrijven
- maar ook af en toe ontsporen
Als ergens in de gegenereerde keten een minder goed token gekozen wordt, dan beïnvloedt dat ook de volgende stappen. Het model bouwt namelijk voort op zijn eigen output.
5. Attention Mechanism: waarom een transformer zo krachtig is
Onder autoregression staat Attention Mechanism in input sequence. Dit is een van de belangrijkste innovaties van moderne LLM’s.
Attention betekent dat het model tijdens het verwerken van een token kan “kijken” naar andere relevante tokens in de input.
Bijvoorbeeld in een zin als:
“De CEO van het bedrijf zei dat hij volgende week het nieuwe model zal voorstellen.”
Als het model probeert te begrijpen waar “hij” naar verwijst, helpt attention om het verband te leggen met “de CEO”.
In langere teksten is dat nog belangrijker. Attention helpt het model om:
- relevante stukken context te wegen
- verbanden tussen woorden en zinnen te leggen
- afhankelijkheden op korte én lange afstand te verwerken
Dat is precies waarom transformers zoveel beter zijn geworden dan oudere taalmodellen.
Heel eenvoudig gezegd:
- niet elk woord in een zin is even belangrijk voor elk ander woord
- attention laat het model bepalen waar het op moet letten
6. LLM ARCHITECTURE: wat het onderste schema wil voorstellen
Onderaan links zie je een groter blok met LLM ARCHITECTURE. Dit is een vereenvoudigde en niet helemaal technisch zuivere weergave, maar het probeert de algemene stroom van een model te tonen.
Input
Links komt de input binnen. Dat is jouw prompt of tekst.
Die input wordt eerst omgezet in embeddings en daarna door verschillende onderdelen van het model gestuurd.
Encoder / Encoder-Architecture
De afbeelding toont een Encoder en Encoder-Architecture. Dat is een beetje verwarrend, want veel moderne LLM’s zoals GPT-achtige modellen zijn vooral decoder-only transformers, niet klassieke encoder-decoder modellen zoals bij oudere sequence-to-sequence systemen.
Dus technisch gezien is dit schema eerder een algemene neural language architecture dan een perfecte weergave van elk modern LLM-type.
Wat de maker vermoedelijk wil tonen:
- de input wordt in interne representaties omgezet
- die representaties gaan door meerdere lagen of blokken
- het model verwerkt context en relaties
- daarna wordt output gegenereerd
Transformer Blocks
Bovenaan in het schema staan Transformer Blocks. Dat zijn de herhalende bouwstenen van moderne LLM’s.
Zo’n transformer block bevat typisch:
- een attention-mechanisme
- feed-forward lagen
- normalisatie
- restverbindingen
Die blokken worden vaak vele keren gestapeld. Grote modellen hebben niet gewoon “een beetje meer” blokken, maar vaak tientallen tot honderden lagen en enorm veel parameters.
Elke extra laag helpt het model om complexere patronen te leren en rijkere representaties op te bouwen.
LM
Rechtsonder zie je LM, wat staat voor Language Model. Dat is het onderdeel dat uiteindelijk beslist welke tokenkansen er uitrollen en welk token als output gekozen wordt.
Je kan het zien als de laatste stap in de keten:
- interne verwerking
- berekening van waarschijnlijkheden
- output genereren
Output
Onderaan komt dan de output. Dat is de tekst die jij ziet.
Belangrijk om te onthouden: wat er als menselijke tekst uitkomt, is het eindresultaat van een lange keten van numerieke bewerkingen en kansschattingen.
7. KEY CONSIDERATIONS: waarom een goed model meer is dan alleen “grote compute”
Rechts onderaan staat KEY CONSIDERATIONS. Dit zijn de belangrijke aandachtspunten bij het bouwen, trainen en inzetten van LLM’s.
Data Quality
“Data Quality” staat er zelfs twee keer in, wat wellicht een foutje is. Maar het blijft wel terecht een essentieel punt.
Een model is sterk afhankelijk van de data waarop het getraind is:
- slechte data leidt tot slechte output
- inconsistente data leidt tot inconsistente antwoorden
- eenzijdige data leidt tot vertekende resultaten
De kwaliteit van een LLM hangt dus niet alleen af van modelgrootte, maar ook van:
- bronkwaliteit
- diversiteit
- actualiteit
- structuur
- ruisniveau
Bias & Fairness
Modellen leren patronen uit bestaande data. Die data bevat vaak menselijke vooroordelen, culturele scheeftrekkingen en onevenwichten.
Daardoor kan een model:
- bepaalde groepen ongelijk behandelen
- stereotypes reproduceren
- vertekende aannames maken
Bias volledig elimineren is erg moeilijk. Daarom is fairness een belangrijk ontwerp- en evaluatiepunt.
Ethical Implications
Dit gaat breder dan bias. Hier gaat het over vragen zoals:
- mag een model bepaalde content genereren?
- hoe ga je om met misinformatie?
- wat met auteursrecht?
- hoe transparant moet AI zijn?
- hoe voorkom je manipulatie of misbruik?
Zeker wanneer AI in zorg, onderwijs, media of beleid wordt ingezet, worden die ethische vragen heel relevant.
Computational Resources
LLM’s vragen enorm veel rekenkracht:
- voor training
- voor fine-tuning
- voor inferentie, dus het effectief draaien van het model
Daarom zijn hardwarebedrijven en cloudplatformen zo belangrijk. Dit sluit rechtstreeks aan bij jouw blogonderwerp over AI-categorieën:
- zonder compute geen model
- zonder infrastructuur geen schaal
Evaluation Metrics
Een model moet geëvalueerd worden. Niet alleen op “klinkt het goed?”, maar op allerlei criteria zoals:
- nauwkeurigheid
- factualiteit
- consistentie
- veiligheid
- bruikbaarheid
- latency
- kost per output
Dat is belangrijk, want een model kan indrukwekkend overkomen en toch zwak scoren op betrouwbaarheid of taakuitvoering.
Fine-tuning & Adaptation
Ten slotte: een basismodel is vaak niet het eindproduct. Organisaties passen modellen verder aan via:
- fine-tuning
- retrieval
- system prompts
- tool use
- agents
- domeinspecifieke data
Dat is precies de laag waar veel bedrijven vandaag waarde creëren. Niet door zelf een foundation model te bouwen, maar door bestaande modellen aan te passen aan een concrete use case.
Conclusie
AI lijkt op het eerste gezicht complex en bijna ongrijpbaar, maar in de kern is het opgebouwd uit een reeks logisch gestructureerde stappen. Van tokenization en embeddings tot neurale netwerken en attention-mechanismen: alles draait rond één centraal principe — het herkennen van patronen en het voorspellen van wat het meest waarschijnlijk volgt.
Wat deze technologie zo krachtig maakt, is niet één specifiek onderdeel, maar de combinatie van schaal, data en architectuur. Door enorme hoeveelheden tekst te verwerken en daaruit verbanden te leren, zijn Large Language Models in staat om output te genereren die voor ons natuurlijk en intelligent aanvoelt.
Tegelijk is het belangrijk om te beseffen wat AI níét is. Het begrijpt geen betekenis zoals een mens dat doet, heeft geen bewustzijn en maakt geen echte afwegingen. Het is een geavanceerde voorspellingsmachine — en precies daarin ligt zowel de kracht als de beperking.
Wie AI wil inzetten in zijn bedrijf of strategie, hoeft deze technologie niet tot in de kleinste details te beheersen. Maar een goed begrip van hoe ze werkt, helpt wel om betere keuzes te maken, realistischer verwachtingen te hebben en vooral: om de juiste toepassingen te bouwen op deze fundering.
👉 Want uiteindelijk zit de echte waarde van AI niet in het model zelf, maar in wat je ermee doet.