Tokens en embeddings: hoe AI tekst begrijpt
Wat zijn tokens en embeddings in AI? Dit artikel legt de basisbouwstenen van taalmodellen uit in gewone taal: wat ze zijn, waarom ze relevant zijn voor praktisch AI-gebruik, en hoe ze je strategie beïnvloeden.

Als je begrijpt hoe AI tekst verwerkt, begrijp je ook waarom het soms perfect antwoordt en soms volledig naast de kwestie zit. De twee begrippen die daarin centraal staan zijn tokens en embeddings — de basisbouwstenen van moderne taalmodellen. Dit artikel legt beide uit in gewone taal, zonder wiskundige formules, maar met genoeg diepgang om betere beslissingen te nemen over hoe je AI-tools inzet.
Je hoeft deze concepten niet technisch te beheersen om AI nuttig te gebruiken. Maar wie begrijpt hoe een model tekst “ziet”, begrijpt ook waarom lange documenten problematisch zijn, waarom context-ramen een limiet hebben, en waarom semantisch zoeken anders werkt dan een gewone zoekfunctie.
Wat zijn tokens?
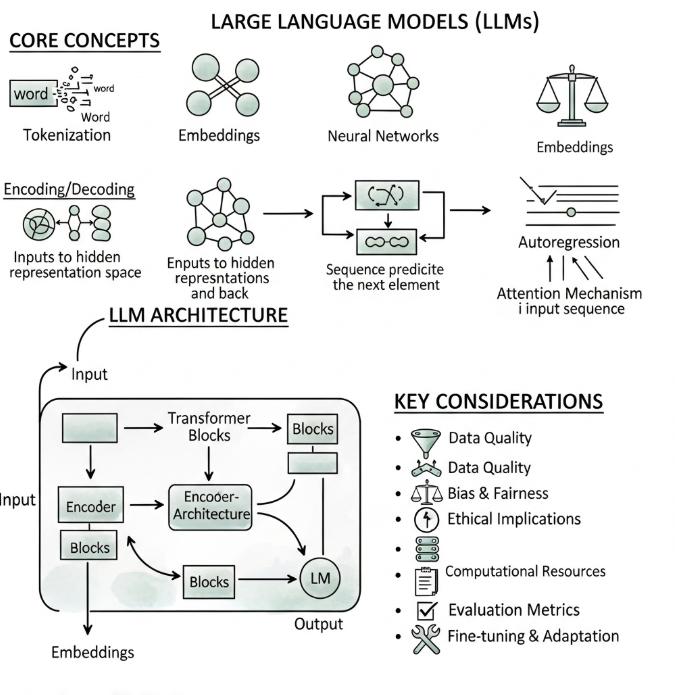
Een token is de kleinste eenheid waarmee een taalmodel tekst verwerkt. Tokens zijn geen letters en geen volledige woorden — ze liggen ergens tussenin. In het Engels of Nederlands is een token gemiddeld zo’n drie tot vier tekens. Het woord “ondernemer” bestaat uit drie tokens. Het woord “AI” is één token. Een zin van vijftien woorden bevat typisch twintig tot dertig tokens.
Waarom tokens en geen woorden? Omdat tokenisatie het model toelaat om ook onbekende woorden te verwerken door ze op te splitsen in herkenbare deelstukken. “Automatiseringssoftware” kan worden gesplitst in “automatisering” + “software” — twee stukken die het model elk apart kent.
Voor de praktijk heeft tokenisatie één directe consequentie: het context window. Elk taalmodel heeft een maximaal aantal tokens dat het tegelijk kan verwerken. Claude heeft een context window van 200.000 tokens — goed voor een boek van gemiddelde lengte. GPT-4o verwerkt tot 128.000 tokens per gesprek. Overschrijd je die limiet, dan verliest het model de informatie die buiten het venster valt — het “vergeet” het begin van een lang gesprek.
Voor jou als gebruiker betekent dit: bij lange documenten of uitgebreide promptketens kan het model context verliezen. Het is een technische limiet, geen fout in je prompt.
Wat zijn embeddings?
Embeddings zijn de manier waarop een AI-model betekenis opslaat. Elk token — elk woord of woorddeel — krijgt een numerieke representatie: een reeks getallen (een vector) die de betekenis van dat token uitdrukt in relatie tot alle andere tokens in het model.
Het resultaat is dat woorden met vergelijkbare betekenis ook vergelijkbare vectoren hebben. “Kat” en “poes” liggen dicht bij elkaar in de embedding-ruimte. “Bank” (financiële instelling) en “bank” (zitmeubilair) liggen verder uiteen, afhankelijk van de context. Dat is waarom een taalmodel “bank” correct kan interpreteren in de zin “ik ga naar de bank” — het model kijkt naar de omliggende woorden om de juiste betekenis te bepalen.

Hoe embeddings gebruikt worden in de praktijk
Embeddings zijn niet alleen een intern mechanisme van taalmodellen — ze zijn ook direct inzetbaar als technologie. De bekendste toepassing is semantisch zoeken: in plaats van exacte woordovereenkomsten te zoeken, vergelijkt het systeem de vectoren van de zoekterm met de vectoren van de opgeslagen documenten. Dat maakt het mogelijk om te zoeken op betekenis in plaats van op trefwoorden.
Concreet voorbeeld: een kennisbank met bedrijfsdocumenten. Een medewerker zoekt “wat is het beleid bij te laat betalen”. Met een klassieke zoekfunctie vindt hij alleen documenten met die exacte woorden. Met embeddings vindt hij ook documenten over “betalingsachterstand”, “wanbetalers” of “aanmaningen” — omdat die begrippen semantisch verwant zijn.
Dit is ook de technologie achter RAG — Retrieval Augmented Generation. In plaats van alle bedrijfsdocumenten in een prompt te laden (wat het context window overstijgt), worden relevante stukken opgehaald via embedding-zoekopdrachten en meegegeven aan het model. Zo kan een AI-assistent antwoorden geven op basis van interne bedrijfsdocumentatie, zonder dat die documentatie volledig in het model getraind hoeft te zijn.
Waarom dit relevant is voor je AI-strategie
Als beslisser hoef je tokens en embeddings niet technisch te implementeren — maar de concepten helpen je betere vragen te stellen bij leveranciers en betere keuzes te maken bij toolselectie.
Tokenprijzen: API-gebruik van taalmodellen wordt afgerekend per token. Weten wat tokens zijn, helpt je de kostenstructuur begrijpen en prompts efficiënter schrijven (korter = goedkoper, zonder kwaliteitsverlies).
Context window als limiet: als je een AI-tool vraagt om een lang document te verwerken, kan het zijn dat de tool niet het hele document “ziet”. Weten wat een context window is, verklaart waarom een samenvatting van 100 pagina’s andere resultaten geeft dan de directe vraag over pagina 50.
Semantisch zoeken vs. trefwoordzoeken: als je een zoekfunctie evalueert voor een interne kennisbank, is de vraag “gebruikt dit embeddings?” een relevante selectiecriteria. De kwaliteitsverschillen zijn substantieel voor complexere zoekvragen.
Voor een bredere technische achtergrond over hoe taalmodellen in hun geheel werken: Wat is een LLM? Grote taalmodellen uitgelegd. En voor de basiscontext over hoe AI technisch functioneert: Hoe werkt AI? Simpel uitgelegd voor beginners. Voor de overkoepelende gids: de AI-gids voor Belgische ondernemers.